


这标题写了后就感觉别扭,大意就是常规采集文本和图片很多小伙伴都轻车熟路了,又开始慢慢的垂涎那些高质量的原创网站的内容了,但是那些网站或多或少现在都做了防采集处理,对于火车头软件使用还不是特别深的童鞋好像就没辙了,今天要说的就是怎么弄那些做了防采集处理的站点。
怎么说呢,我不想传播做站都靠采集的思想,照搬来的东西或许你自己都看不懂有什么意思呢,所以这里还是提倡尊重原创,文章里的内容仅限交流讨论吧,火车头采集的文章浅陋的也写过几篇了,常规的东西今天在这里不打算老生常谈,这里吧标签链接贴出来,对基础东西还没大掌握的同学可以先了解下,再来看这篇文章吧, https://www.sweetdan.com/category/huochetou
这里举三个例子,每个情况都不一样,值得拿出来分享交流的,所说的仅限到目前为止该网站的源码。后面有什么改动那可就不得而知了,你弄了他还不准别人弄你么,懂就行, 我做b2c的所以例子都是欧美综合电商网站,
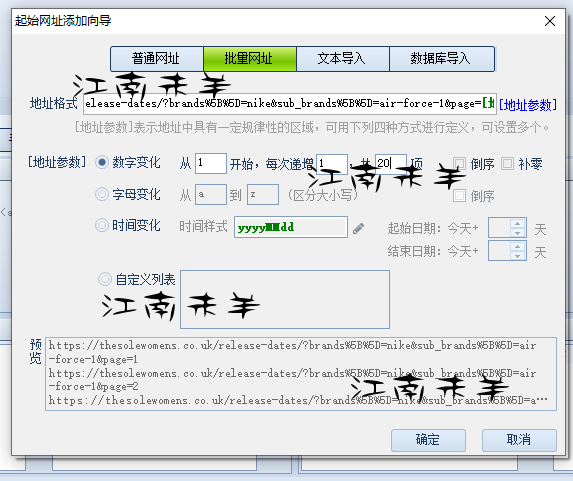
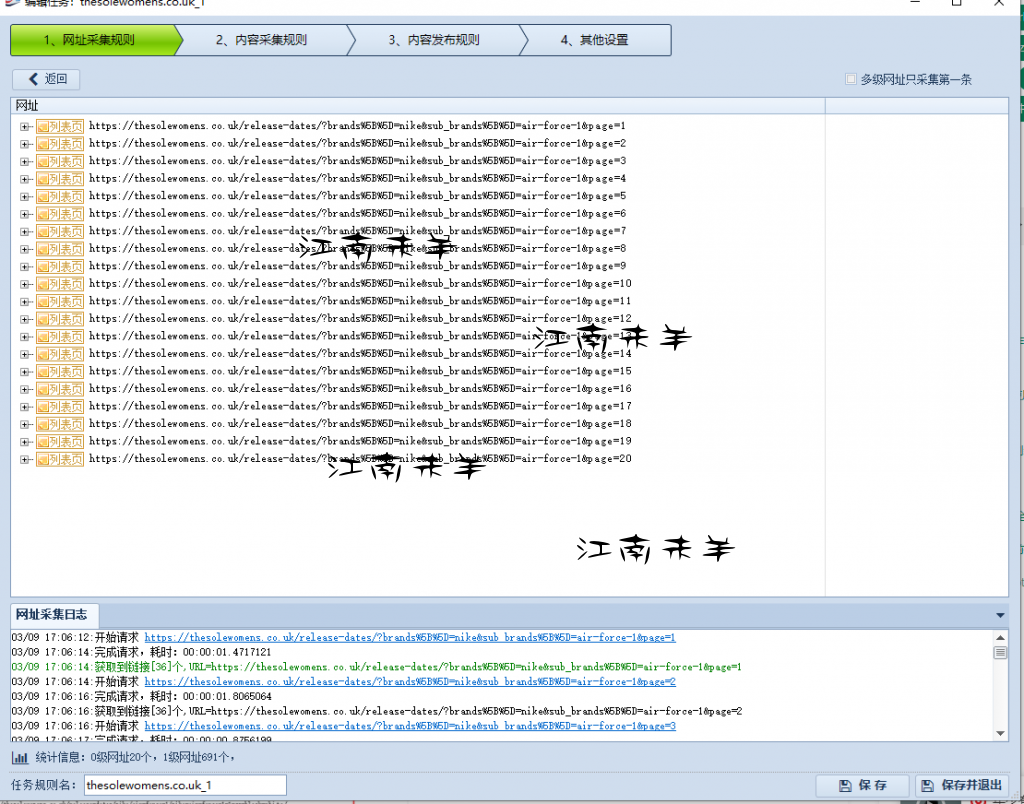
第一个是,thesolewomens.co.uk,主要体现在数据处理替换上。首先看它的分类链接 就就知道获取分类网址就很简单了。直接网址多页。page=*, 等差,值是1.,写好区域和限制字符,测试下成功就ok了,没任何难度不多讲了如下所示,
https://thesolewomens.co.uk/release-dates/?brands%5B%5D=nike&sub_brands%5B%5D=air-force-1
https://thesolewomens.co.uk/release-dates/?brands%5B%5D=nike&sub_brands%5B%5D=air-force-1&page=2

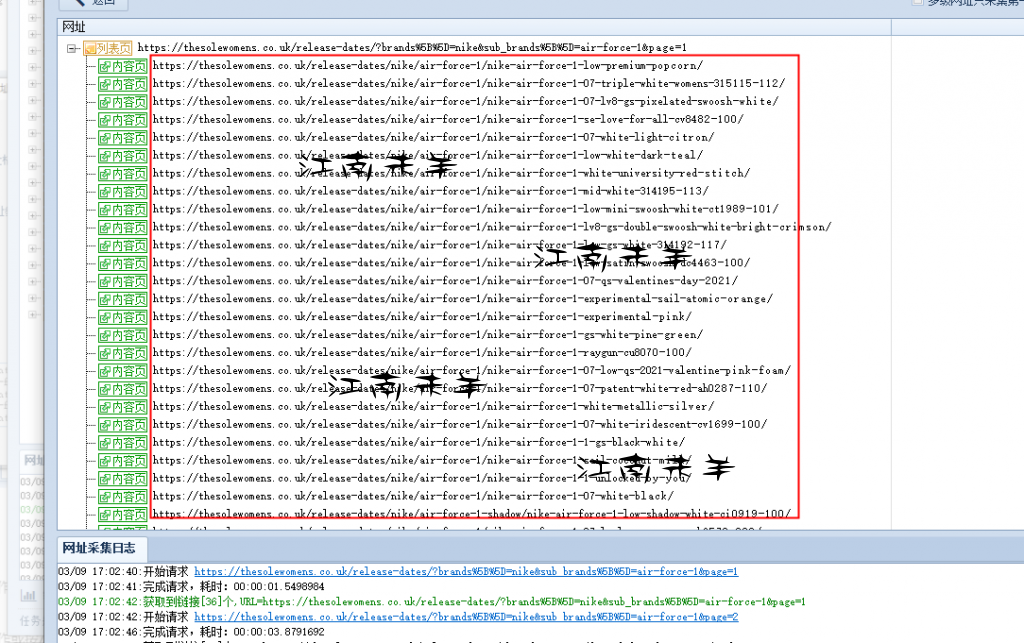
分类网址采集没问题后,下面就设置页面内容采集规则了,标题,描述,原价,编码,这些都是文本字段。找相应的独特标签。用前后截取方式就可以准确无误的获取到想要的字段了,不赘述这部分。然后就到了主图部分,你会看到要是不
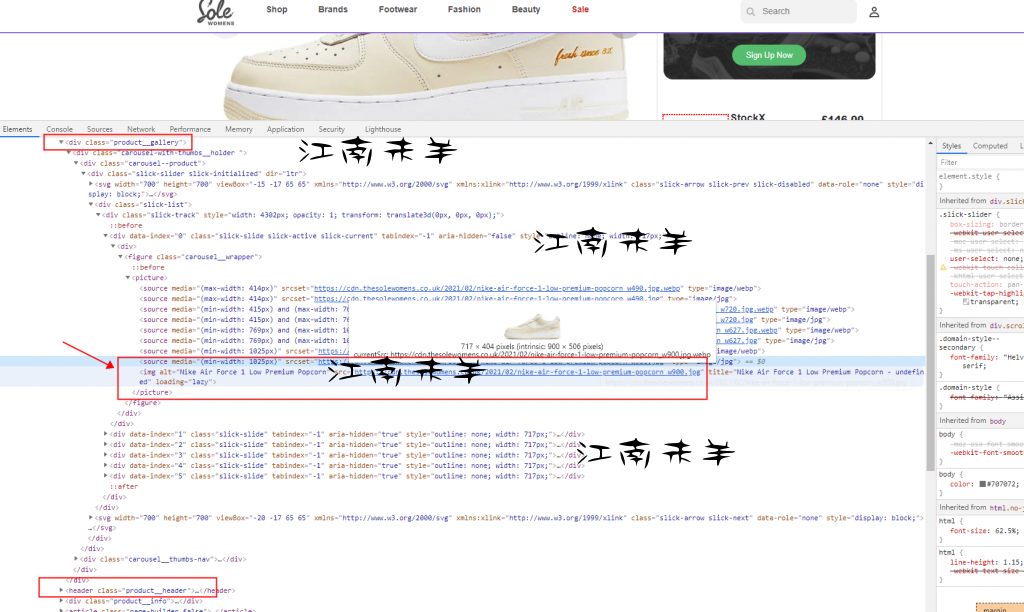
未完待续…
通告:火车头采集器采集规则,详细使用教程,实例教学 – 江南未羊