

!提示:我这边可以提供采集服务,中英文都可以,需要的话欢迎来询。微信:yangtuo1991
作者写过几篇火车头。有简单介绍,也有复杂点的,需要浏览的话可以到火车头分类链接:https://www.sweetdan.com/category/huochetou
好了,言归正传,接下来讲解火车头采集器的详细使用方法和技巧。这里直接给大家贴出作者使用的这个版本的火车头,(需要联系作者)
简单说采集主要分为几个步骤进行,首先了解每个步骤的工作原理和任务目标,就能很好的熟悉这个采集器操作了。
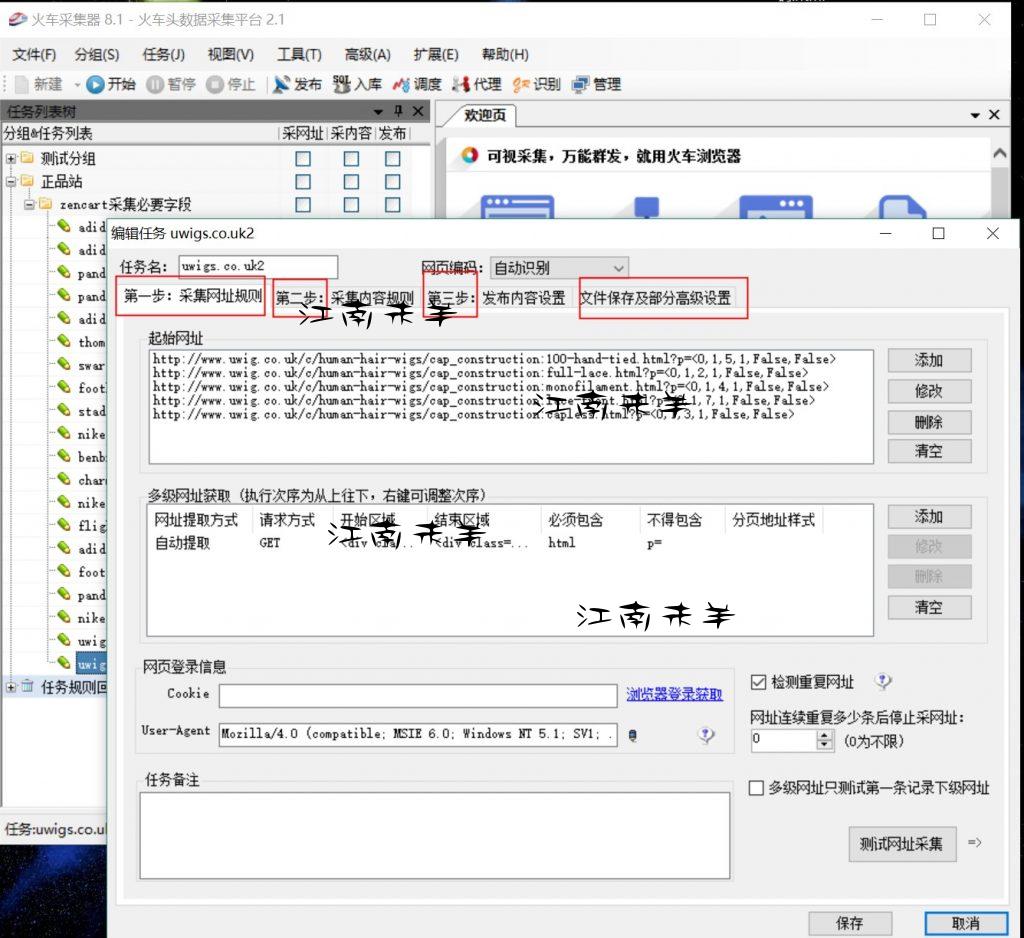
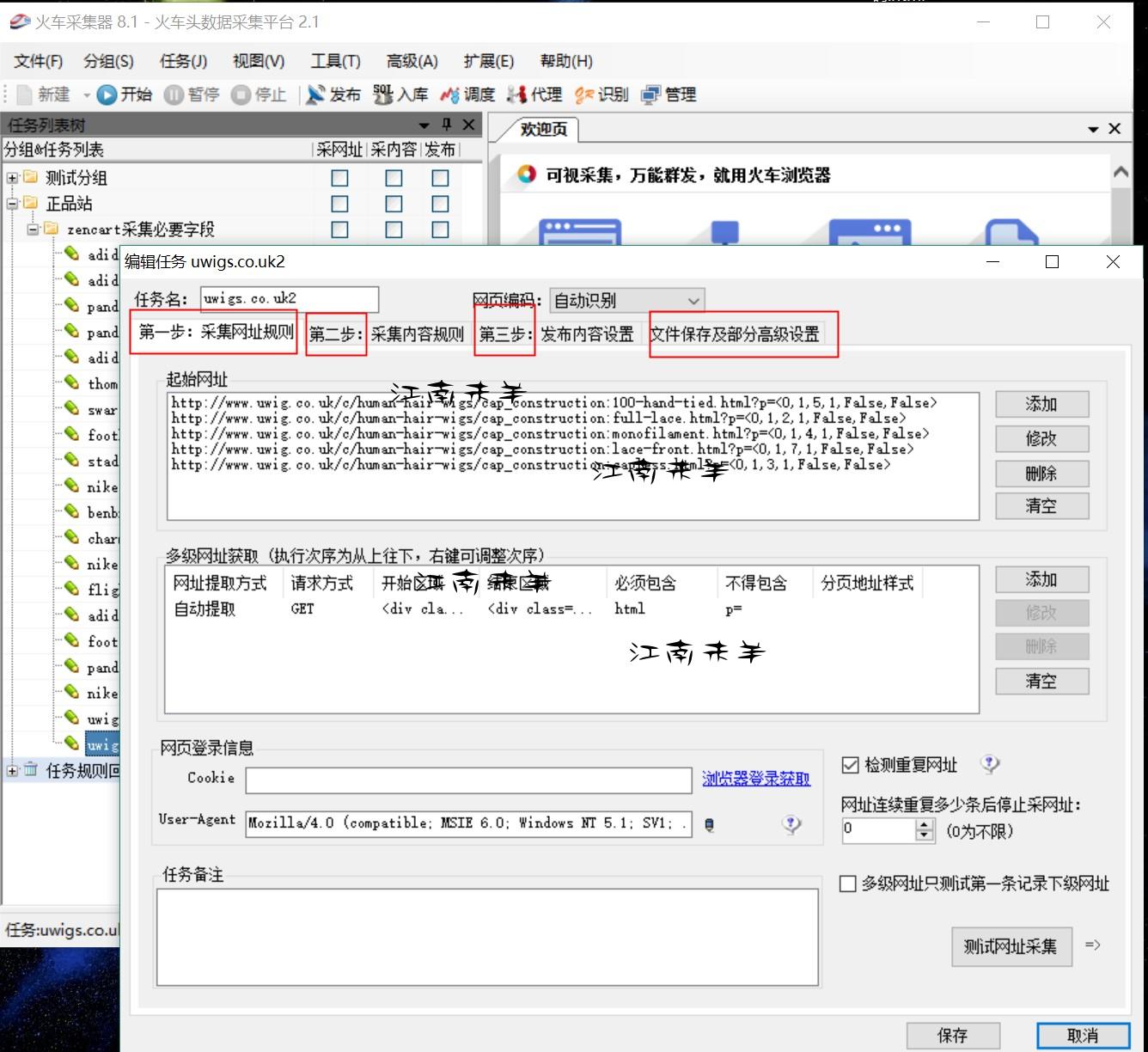
如图所示,作者圈出来的主要也就三个步骤加上最后表格保存及一些列的设置。下面就一个一个来讲。
首页就是第一步,采集网址规则,按逻辑关系来说,采集器想要采集每个网页上的内容之前是不是先要获取到这些页面的URL,获得这些网址之后采集器才能到一个个页面上去采集你想要的内容。那么问题就简单了,我们首先要获得分类页面上展示的这一个个产品链接,就要打开一个分类页的源码,然后找到这些产品代码的区域段,在区域段的上方和下方个找一个唯一性的标签,这样就能成功的截取到我们想要的这类产品的一个个链接了,有时候还要配上包含字符和不包含字符等等,(一些做了JS的网页的情况又是不一样,这个情况另行讨论),下面作者拿实例图给大家做展示说明:
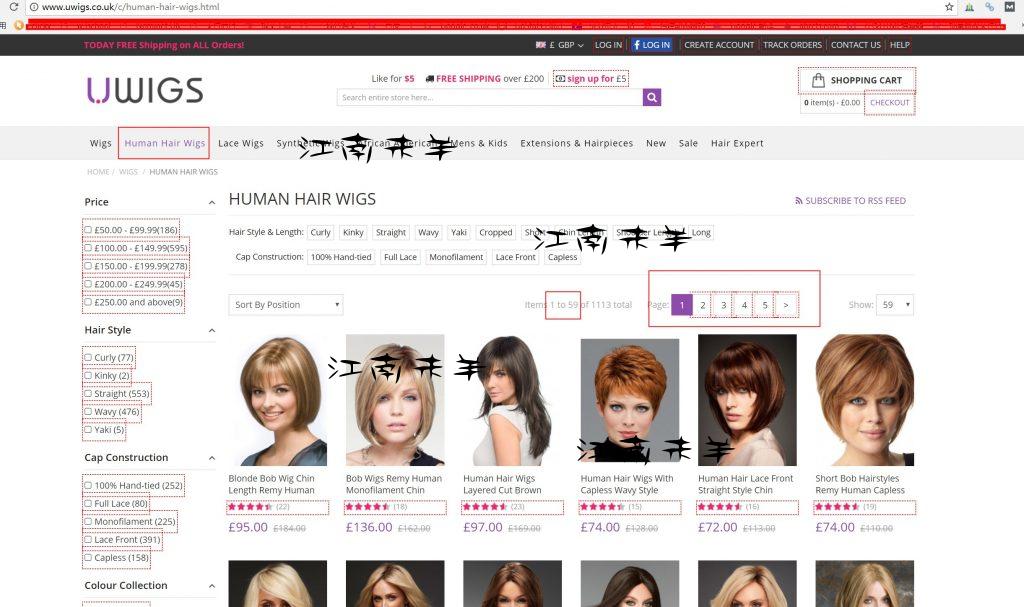
假设我想采集这个假发站点的human hair wigs这一类产品,我点开这个大类后看到一共分为5页,每页展示的是59件产品,我现在首先要把这5页的产品的URL作为我的目标URL,建立任务,如下图所示,

目标网址建好后,就需要填写目标网址的代码筛选规则了,
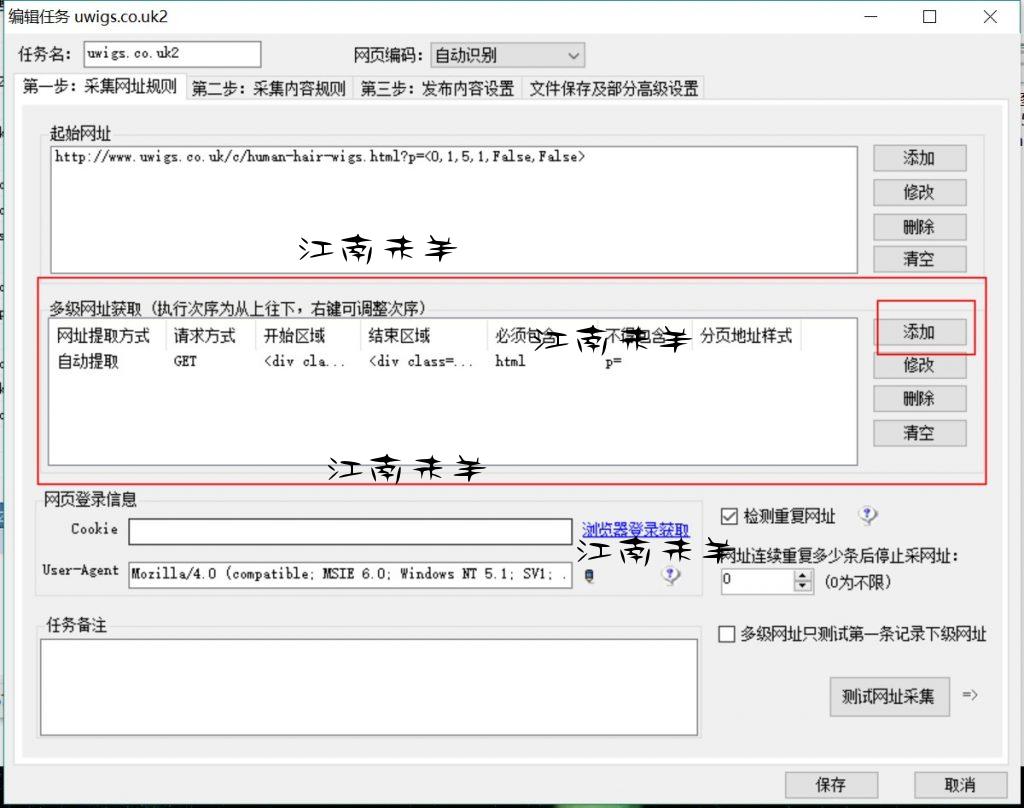
点击添加之后,就来到了具体填写规则的界面了,如下图,
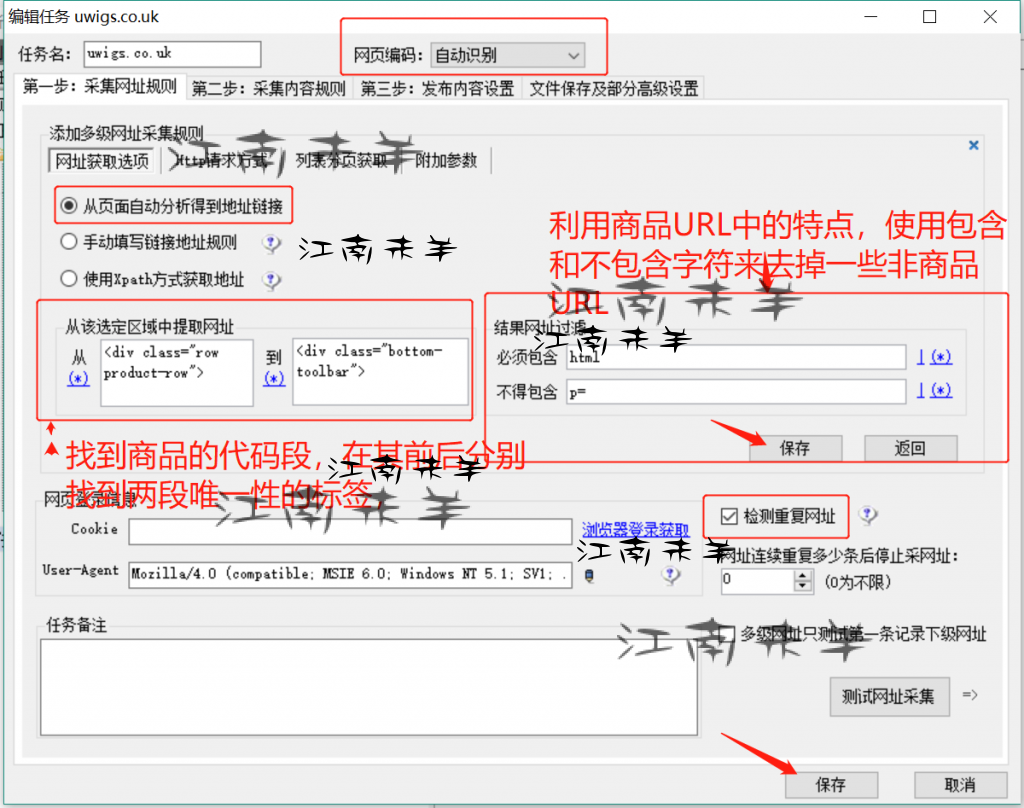
注:商品代码段的前后标签最好是唯一性的标签,当然了,不是唯一的也可以,不过需要注意利用包含和不包含字符来去除掉多余的URL,
保存好页面商品的采集规则后,点击保存后,采集网址规则这一部分就完成了。
下面就到了采集内容规则了,这就是具体产品页面的采集了,
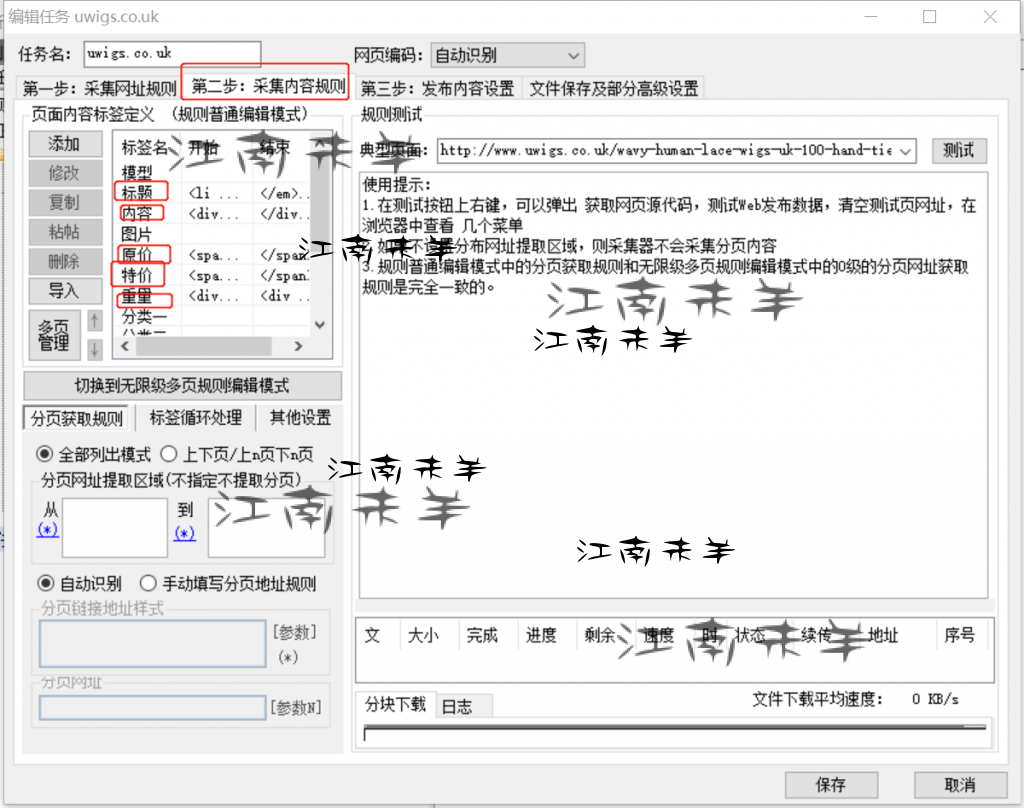
众所周知,想采集好一个具体的商品页面,需要采集 标题,图片,小图,价格,描述,特性,等一些常规的和特殊的一些信息,拿这个假发例子来说,就收集了标题,属性表,原价,特价,主图,小图,描述这些信息。
这些具体的单向信息采集,例如标题,属性表,特价,原价,描述这些都可以使用元素前后截取的方式来获得,如图
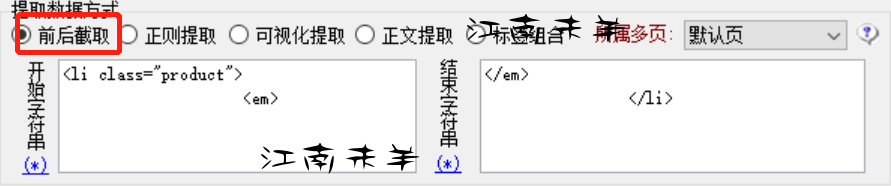
然而主图和附属图,在图片代码简单的情况下也是可以使用前后截取的方式,但是为了避免不明情况的疏漏还是建议图片的采集使用正则提取,如下图
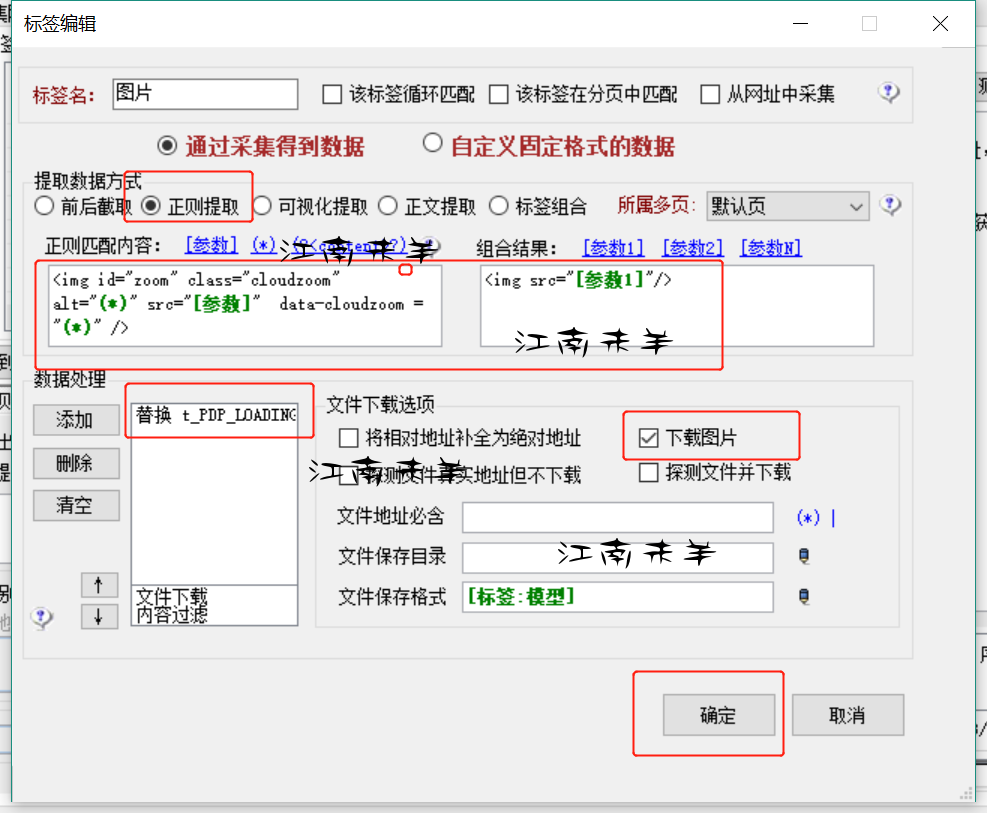
注:把图片代码段的变量都使用星号代替,若要对图片进行处理替换的话,可以在左下角有功能让你选择(例,有时候图片的URL打开时就很小,你可以替换下图片的尺寸,通常就会有大尺寸的图片URL供你使用)。
好了,第二步的采集内容规则讲完了,下面就到发布内容设置了,没有什么特别需要说明的,根据自己的需求来,如下图,
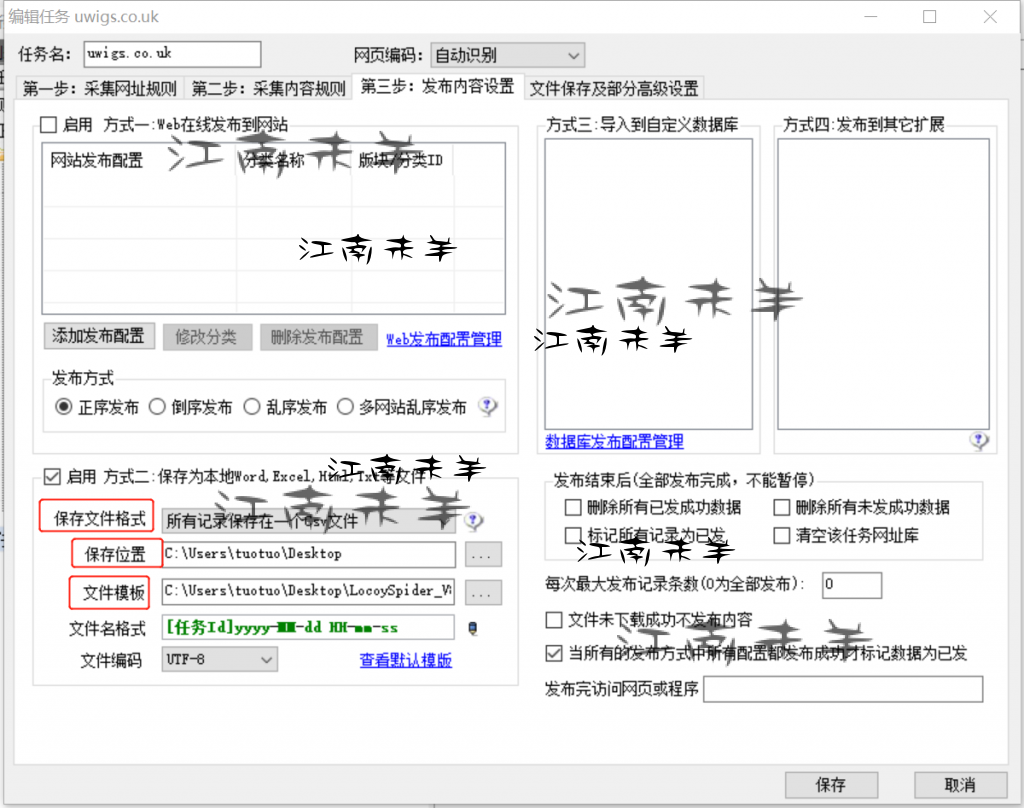
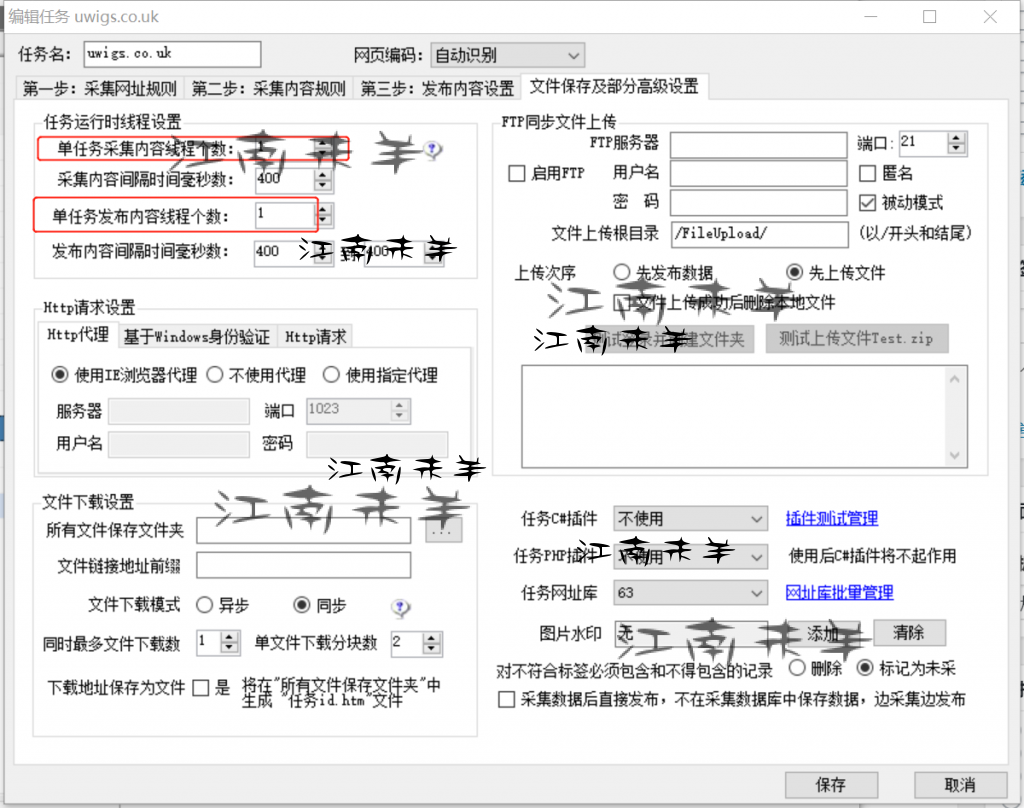
额外讲下,这个文件保存及部分高级设置,有些用户在采集的时候需要维持原数据的顺序,这时候在高级设计选项里面,就需要把单任务采集线程个数设置为1,要是为其它数值的话,就会有多线程同时采集了,那样就没法保存数据的顺讯排列了。如图吧
都设置好之后就可以选运行,采网址和才内容,然后再勾选发布,数据表格就会发布到你设置的保存位置,如图,
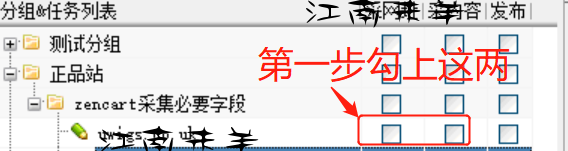
然后右键,菜单选项,开始任务,就好了
完了之后再勾上发布,右键,菜单选项,开始任务,就完成了。
具体细节和问题可以询价和交流!
然后贴几篇大家可能会需要的,感兴趣的话可以直接点击前往就可以了
感谢分享